各位C照没考过的真的可以去死了
新西兰的狗狗都会开车了。还手动档的哦亲!!!
Posted
archive
This blog is rated 🔞, viewer discretion is advised
新西兰的狗狗都会开车了。还手动档的哦亲!!!
Posted
archive
信息一
信息二:
现查明,你公司擅自扩大国内因特网虚拟专用网业务覆盖范围,违反《电信业务经营许可管理办法》(工信部令第5号)第十六条规定,未取得国际通信业务经营许可、擅自与香港一公司合作跨境经营因特网虚拟专用网业务,违反《电信条例》(国务院令第291号)第五十九条和《国际通信出入口局管理办法》(原信息产业部令第22号)第十九条、第二十五条规定,依据《电信条例》第七十条规定,决定责令你公司改正违规行为,并处一百万元罚款。
信息三,注意这个2003年就出来了。
第二十二条 以经营电信业务为目的,通过互联网国际出入口设置虚拟网络的,应当报信息产业部批准。以内部使用为目的,通过互联网国际出入口设置虚拟专用网的,应当报信息产业部备案。
是不是觉得tg碉堡了?
btw 大家一定注意一个公司 烽火网络Fiberhome.com.cn via ITU大会上的 Y.2770 就是他们搞的。
Posted
archive
马克一下。。。exec这个没想到shell里也可以用啊
exec 3<>/dev/tcp/www.google.com/80
echo -e "GET / HTTP/1.1\n\n">&3
cat <&3
简单的端口扫描:
$ for p in {1..1023}; do(echo >/dev/tcp/localhost/$p) >/dev/null 2>&1 && echo "$p open"; done
btw 最近看到好多openvpn被k掉了。看了下sshd的[源码](xasprintf(&server_version_string, "SSH-%d.%d-%.100s%s%s%s",)
这一行:
xasprintf(&server_version_string, "SSH-%d.%d-%.100s%s%s%s",
真尼玛坑爹,真心不安全啊。还是brl的patch好用。
Posted
archive
场景:有多个github账号,比如公司一个,私人一个。现在想在同一台主机上同时维护公司的和私人的repo
大家可能会尝试把一个公钥贴到两个github账户,实践告诉我们
Key is already in use
解决办法:
ssh-keygen -t rsa -f ~/.ssh/id_rsa.est编辑ssh_config vim ~/.ssh/config 粘贴下边的东东:
Host estgit
HostName github.com
User git
IdentityFile "~/.ssh/id_rsa.est"
IdentitiesOnly yes
用这个方式来操作git:git clone estgit:/username/repo ,或者编辑 .git/config 里边的 remote - url
原理就是,指定一个ssh的Host的单独IdentityFile,然后因为git是基于ssh的,所以用Host名称连接github.com就会用那个单独的公钥了。
github真是好东西,免费的网盘啊有木有!
Posted
archive
看到这个报道 封锁OpenVPN与加密流分类的学术论文
突然觉得几年前的事情现在应该又走到了一个拐点。
6年前我们会用squid都很容易绕过限制了,然后是socks,加密socks,dns还原,然后是ssh,openvpn。
现在都开始搞机器学习来封锁了。
那么这就是一个策略问题了:
所以,任何公开的破解策略,都会最终被封锁技术打败。
以后的破解,一定是地下组织,单向联系,各自之间无交集,经常变换自定义二进制协议隧道。
这样才有的搞。
btw 另外我觉得大家应该学习下SVM投毒。这个是未来的必要生存手段。
bbtw 另外slashdot上这帮人开始思考人脑投毒了。认知科学和心理学的逆袭?
bbbtw 关键字:adversarial machine learning
最后,让我们端起手中的热翔,为这片奇葩的土地翻开新的一页,干了它!
Posted
archive

最后那个 (╯°□°)╯︵ ┻━┻ 真是破坏这么好一片文章了。
Posted
archive
用了好几个chrome的time tracking扩展,用来跟踪我上网都把时间浪费在哪些网站上了。
这几天的发现:
这是跟进程线程有点类似啊,context switching贵啊。。80%的核心任务其实只花20%左右时间。
过几天有其他心得继续补充。目前发现比较准确的扩展是这个:
https://chrome.google.com/webstore/detail/web-timer/ggnjbdfgigejghknieofeahaknkjafim
其他扩展,要么跟踪不准确,比如一天下来只算了40多分钟的上网时间
要么2年没更新了。
其实这些扩展都不是很好,主要的问题是
我有点想挖个坑自己去轮这个了。最好的time tracker应该是7x24无侧漏全覆盖的。展现形式应该有
其实timeline是我最想要的~~~tab切换之类的可以直接通过一段一段方块展现出来~~~
其他的几个功能:
Posted
archive
看到一条微博
@互联网的一些事 : 马化腾说过:“在腾讯不允许说什么事情在技术上做不到。”
让我想起来了这个经典的XY problem,今天恰好又在reddit上看到了
什么是XY 问题呢?用一个例子说明
提问者:什么函数能返回两个分隔符之间的字符呢?
路人甲:没有直接搞这个的函数吧?
路人乙:split 然后 slice
路人丙:partition也可以
提问者:我试过 partition
提问者:原始字串字符是这样的 "attribute1: 50.223, attribute2: 442.1",现在我想得到50.223
路人丁:为啥不直接写个函数来专门解析这样的字串
提问者:有没有自带函数能直接搞定这个呀
路人丁:pairs = [x.strip() for x in s.split(",")]; attribs = {k: v for x in pairs for k, v in x.split(": ")}
路人丁:还有一些库可以解析各种格式的字符串的。
路人丁:比如 json或yaml
提问者:字串是来自html里边的
提问者:但是我想找一个能解析Javascript的HTMLParser之类的
路人丁:是需要解析一段html里的javascript,还是解析各种变形的html?
提问者:是解析嵌入html的javascript
路人丁:你去查一下json是不是差不多?
提问者:呃,好像这的就是json。学习了。
路人丁:解析json的库多了去了随便用一个
提问者:果然如此。谢谢
回到本帖的主题,如果马化腾真说过这句话,那么看来腾讯这个PM说了算的帝国果然名不虚传。
大多数PM定制的需求就是把用户的X问题,用自己的2b能力包装成了Y需求,然后苦逼码农在功能上做出了打折扣的Z实现。
Posted
archive
This is what you do when you have a shitting Internet connection:
$ vim ~/.bash_aliases
function retry(){
false;
while [ $? -gt 0 ];
do $@;
done;
}
To rape your server, just retry ssh -o ConnectTimeout=1 blah@foobar
Shit just got working for now.
Posted
archive
dump一个db的时候发现有个 INT 类型居然保存的数据是 20121126
问了下,对方说,就是这个样子设计的,方便用来比较日期
我这种老实人都是老老实实datetime类型,看好时区然后UTC的timestamp转换,最后才比较的。。。
对方丢了一句:
还不是一回事。。。效率还高一点
想了一下,我擦,果然。
20121125 < 20121126 直接这样啊有木有!单位数月份也可以比较。
对方又丢了一句,连用string直接比较都可以。
算是领教了神代码,彻底打败了。被这种糙快猛开发爆出翔了。
Posted
archive
从HN上看到这篇帖子 What Has Changed,觉得对未来很糟糕的样子。
特别是这一段:
the consumer web has matured. we are almost 20 years into the consumer web and we have large platforms that are starting to suck up a lot of the oxygen. google, facebook/instagram, amazon, microsoft, apple, twitter, ebay, yahoo, AOL, craigslist, wordpress, linkedin together make up a huge amount of the time spent online, particularly in the english speaking world. there are still occasional new entrants into this list and departures too. tumblr and pinterest have risen a lot in the past couple years while myspace has declined. but consumer behaviors are starting to ossify on the web and it is harder than ever to build a large audience from a standing start.
我觉得有必要限制上边提到的网站的使用时间和频率了。这真的是 suck up oxygen 浪费时间。
另外就是发现了这个 VoiceBunny ,这对国内一帮开podcast的喷子比较有启发吧。我还是比较欣赏这样的媒介形式的。我比较想上下班路上听听神侃。。。
但是感觉VoiceBunny这种在国内也火不起来,国内搞有深度的,拼【质】的东西,容易被靠spam堆【量】的东西秒。。。。所以也很少有人花代价去买这种专业语音服务。
上一个周末花了 $6 买了个invitation设计,感觉很亏了。国外这种stockphoto, design交易市场真的很发达,国内没有这种 职业服务 交易市场,都还是物品/虚拟物品交易为主。不过 @avc 文章对 @voicebunny 的巨大推广作用也是一个成功营销的典范。值得学习~~
PS: 后续讨论:
There are two kinds of apps: entertainment and utility. Retention is not a problem on the latter, almost by definition impossible with the former. How many movies would you watch every day of your life?
Posted
archive

Video exported from Lumix GF2 using Handbrake, GIF created using Cliplets.
Posted
archive
按照这个帖子,挖个坑
现代网站架构一般不能缺这几个东西:
而这一切都可以在一个强大小巧稳定的Web服务器主进程中实现。这就是适合我这种偏执狂滥用的东西——uWSGI。
以后慢慢写了
Posted
archive
以前感谢一位名叫lol的网友得到了两个RTL2832U dongle开始玩rtlsdr
这玩意的参数是:
关键是很便宜,大概$10左右。
今天无意中又翻到另外一个HackRF更加碉堡了。大概是$300左右价位,DARPA资助,具体参数为:
更喜欢HackRF的原因是其带宽。DMB-TH的带宽是4.813 Mbit/s - 32.486 Mbit/s,所以rtlsdr没法搞这个。
HackRF在github搞软件开源,同时也有硬件开源,很有意思。
Posted
archive
So if you want to write a Queryset in Django like this:
models.MyModel.objects.filter( Q(a=1) | Q(b=2).extra(where=[""]) )
It desn't work, because extra() can not be used on a django.db.models.Q object
Instead, you can write like this:
qs = models.MyModel.objects.filter(a=1)
qs |= models.MyModel.objects.filte(b=2).extra(where=[""])
I guess it's cool.
Posted
archive
Instasll new shit on legacy OS is always pain in the ass.
Uwsgi 1.4 includes some awesome new features using zeromq, but it's impossible to install directly using pip. So here's the patch
dpkg -i that shitAaaaaaand you are done.
Ubuntu Lucid 10.04.2 LTS is such old system, even the libc6 is lack behind, A LOT.
Posted
archive
几天前看到这个新闻:
知名FreeBSD开发者、 Varnish web-server缓存作者Poul-Henning Kamp认为,开源软件的市集开发模式(见ESR的《大教堂和市集》)创造了一代只知道拷贝粘贴的无能IT专业人士,混乱的软件毁灭了优雅的Unix教堂及其著名的简约设计理念,他认为一代人迷失在了市集中。Theregister的评论称,无数采用GPL许可的开源软件分裂,Linux没有分裂是因为它有一个强有力的、富有魅力的领袖Linus Torvalds,但Linus只有一个,很少有开源项目拥有类似Torvalds那样的领袖。
今天又在reddit看到一则讨论,github上一个top 5加星的项目,为什么会死掉?
原作者看得出来是充满了怨念愤怒恨的。引用:
A terminal run off a websocket with complete decoupling of front and back-end ignores network transparency? Yeah see, stupid comments like these are why I stopped working on it. People never understood how much of a research prototype this was. Enjoy your VT100 terminal which still pretends to be a fucking teletype printer in the 21st century.
(顺便说一下这个reddit链接指向的blog的3D页面滚动效果真他妈炫。帅得掉渣。卡逼的时候,老子还以为我的鼠标坏求了。)
让我又想起以前看到的git的问题是什么:
Power for the maintainer, at the expense of the contributor
有的时候觉得 git 就是Linus发明出来一个鞭子,
Posted
archive
微博上看到这个段子,赶快收集下来了。
Posted
archive
前几天从CSK的微博看了这个视频
今天看到一个讨论:
发信人: i3721pp (noosa), 信区: Aero
标 题: 王华明的报告“航空高性能大型复杂整体构件激光直接制造技术研
发信站: 水木社区 (Mon Nov 12 23:16:08 2012), 站内【 以下文字转载自 MilitaryTech 讨论区 】
发信人: navigate (逆水行舟), 信区: MilitaryTech
标 题: 王华明的报告“航空高性能大型复杂整体构件激光直接制造技术研
发信站: 水木社区 (Mon Nov 12 22:16:10 2012), 站内这个有这么神么 ?
王华明的报告“航空高性能大型复杂整体构件激光直接制造技术研究进展”
http://www.casad.cas.cn/document.action?docid=12916
内容提要。
1。2012年奥巴马在卡内基梅隆大学,宣布创立美国“制造创新国家网络”计划,成立1
5个制造创新中心组成网络,投资10亿美元。经过5个多月的论证最后还是选了“增材制
造”作为第一个中心的研究方向。2。一个发动机叶盘,传统工艺制造属于“雕刻”,最后剩下来的只有7%。
3。f22钛框,面积5.53平方米。3万吨水压机模锻件能达到0.8平方米,8万吨能达到4.5
平方米。4。传统方法,铸锭,制胚,模具,模锻。举例一个很小飞机框,宝钢等温锻造,模具7
千万,分摊到每一个零件,模具费就有几十万。又举例美国的一个飞机零件,压成一个
饼3吨,到最后加工完成只有144公斤,材料利用率不到5%。5。用他的增材制造,材料利用率80%左右。
6。我们打印出的最大的整体结构件5平方米,美国做不了。
7。激光打印出的零件,超过或者等同于锻件的性能,抗疲劳强度,比锻件高32-53%,疲
劳裂纹扩散速率降低一个数量级。常规性能和锻件差不多,但高温、持久、抗疲劳性能
比锻件好很多。8。飞机起落架的超高强度钢,用此方法抗疲劳强度可以比锻件高20%。涡轮叶片用此方
法900度疲劳强度可以比第二代单晶高40%。9。应用方面,2005年开始,919是可以说的,其他的都不能说(涉及保密)。919,双曲
面窗框,只有欧洲有有家公司能做,周期2年,先付200万美元模具费,而且零件非常贵
。而我们55天就做好了,4大件,2件已经装上了飞机。10。翅膀根的受力件,我们做出来136公斤,锻件1706公斤,节省材料90%+,节省了大量
材料。10年,已经做完了性能测试,比锻件还要好。11。05年做出图示零件(猜测是军用飞机上所使用),需要5天,现在只要几小时。
12。06年某飞机起落架的关键零部件,目前已经批生产,已经受2000多个起落。如果没
有这个技术,这个飞机就出不来,可能要推两年。13。某飞机上非常复杂的一个零件,钛合金,一架飞机好几个,现阶段传统技术无法做
出来,国内三种方案去研究,两三年不成功,后又去找国外。国外先说能做,看到图纸
以后,说做不了。我们临危受命,去年5月19号开始,现在已经装了很多架飞机。14。某飞机零件原来锻胚580公斤,我们做出来36公斤。580公斤锻胚,我们没有这么大
的锻造装备,锻不透,性能都不合格。就算加工出来,内应力很大,变形、开裂,成品
率非常低。15。(吐槽f22),f22的机翼和机身连接件,超大超复杂的钛合金构件,因为太复杂20
、30万吨的水压机也做不出来。美国人就分成三个铸件,然后热等静压再焊接,铸件的
性能很差,但美国人没办法,f22就是这样用的。(换了一个图片)我们激光成型就可以
直接加工出如图示的这么大的零件,这是一个整体(意思是不用分段铸造然后焊接),
上面站了一个人,大家可以看出它的尺度。他的性能比锻件还好(意思是当然就甩铸件
几条街了),可以毫不谦虚地说,这是迄今世界上性能最好的、结构最复杂的构件,美
国人也只能是铸造,锻是不可能的,焊也不可能,因为焊出来的性能不行。这个已经通
过了8000小时的疲劳试验,一年多时间。就这个构件,铝合金、钢大家看看能不能做出
来,更何况钛合金。16。我们发动机不行,心脏病,未来发动机就是一肚子的整体叶盘,叶片和盘子分开的
重量太重。而我们现在可以叶片和盘子同时出来,而且叶片我们可以随心所欲控制组织
,让它长成柱状晶,他的高温性能就很好,这里我们让它长成等柱晶,**疲劳度就很好
,如果温度再高,我们就可以换材料,它可以做到随心所欲,一种零件可以用很多种材
料来做(不知是在同一个零件上的不同部位,还是同一种零件用不同材料)。17。我这里面都没说具体的零件名称,牵涉到保密的大家都不要说,也不要拍照。我尽
量做到没有放(图片)零件,只放毛胚,因为零件还是比较敏感。18。这种加工方法,不能包打天下,适合难加工的、高性能的、贵的、别的方法做不出
来的零件,优势是成本、周期、性能,这个方面我们走到了美国人前面。19。设备用的激光器都是进口,担心被美国人卡脖子,希望国家在大功率激光器上重视
。20。5年前曾经和飞机总设计师聊天,说我们快速设计飞机,都是整体、大型、超长的结
构,在2、3个月内就把飞机造出来,不开一套模具,不打一个锻件,不做一个焊缝。也
许有人认为这是个梦想,但实际上这已经不是梦想了,我们已经有这样的潜力,只是目
前能力有限。(这一段其实是欲言又止,应该是涉及保密,只好把能力藏着掖着了。这
件事肯定在做,最近航空大爆发,绝对和他们这个技术有关。)
3D打印果然是第四次工业革命的开启者啊。我擦。
Posted
archive
突然觉得这个joke好经典
@法门寺释者慧:#禅宗公案#武士手握一条鱼到一休禅师房间说道:“咱打赌,我手中这鱼是死是活?”一休知道若说是死的,武士定会松手;而说是活的,武士定会暗中使劲把鱼捏死。于是一休说:“死的。”武士把手松开,笑道:“哈!你输了,鱼是活的。”一休淡淡一笑道:“是的,我输了。”但是他却救了一条实实在在的鱼。
@冥王哈:#禅宗微小说#一天,一个武士抓着一条活鱼来找禅师,说:“你猜这是活鱼还是死鱼,如果是活鱼我就杀了它。”禅师不想打诓语,又不能害了这只鱼,便十分苦恼,深深思考,半小时后,禅师说:“是死的。”武士看看手中的鱼,说:“你妹啊!半个小时前活着呢!”
Posted
archive
在帖子里包含以下特殊字符,你有80%的可能性日掉各种写得不好的xml解析器:
官方文档在这里 http://www.w3.org/TR/xml/#charsets
Char ::= #x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF]
Posted
archive

大图:http://att.newsmth.net/att.php?p.107.51216.290.jpg
tg是不可能被大棒轻易敲掉了。
Posted
archive
就是在街上和任意陌生人对话,装作认识
Posted
archive
我去看了下,的确太强了
发信人: temporary (昙花一现), 信区: NetNovel
标 题: 网文自动化到这种程度了咩
发信站: 水木社区 (Thu Nov 8 15:32:29 2012), 站内码字辅助工具
http://xuanpai.sinaapp.com/work/随便试了下境界的自动生成,给跪了,一个字:比我强
估计这样发展下去,结合tvtropes.org的思路,电视剧编剧可以下岗了。
做游戏什么的直接一按,物品道具法术什么的就直接出来了
Posted
archive
I have a overal negative review on To-Do & GTD apps on android . Today I tried Astrid Tasks (com.timsu.astrid). It was a mess
That was quite a disappointment.
Posted
archive
首先看到 这里 http://www.hi-pda.com/forum/viewthread.php?tid=1071697
Hi!PDA论坛坛友francisngl发布了一篇有关预测Surface前景的文章
然后被tech2ipo转,然后被cnbeta转:Surface必将惨败三理由:用户不待见,核心竞争力低下,硬伤明显
我艹什么破玩意。
然后又看到 http://www.v2ex.com/t/51825 这里,装马甲发帖。
来自匿名人士hackerTom的这篇文章能让我们从一个更加直观的角度向大家讲述一个与以往大家认知截然不同的创新工场和李开复形象,Ta告诉我们为什么创业者不要选择创新工场。
tech2ipo这算什么破鸡巴网站。整天发些什么破鸡巴帖子。
Posted
archive
看到一则消息 http://weibo.com/1895520105/z3MDU9728

据说是小米TV。
不管内容实质如何了,但是我希望有几个功能:
其他软件能实现的功能就不多说了。如果都做到了成本控制在500元以下,直接秒杀一切客厅设备了。
然后,然后我的梦就醒了。
Posted
archive
这他妈不科学。
Posted
archive
家里有个老机器 海美迪HD 300B,用的是Realtek 1073DD+方案,发现一个很猛的固件:
http://www.hdpfans.com/thread-120536-1-1.html
吐槽一下,DLNA被国内翻译成 多屏互动 。搞了半天我一个关键字搜索不到是这个原因。。。囧。
刷机之后真的能支持了,Win7上网络设备刷出来一个
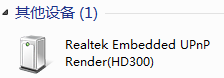
连WMP和BubbleUPnP都支持很好。赞美一个。
继续玩Intel UPnP Device Spy想到一个比较好玩的功能:
SetAVTransportURI() 是支持任意HTTP地址的,而很多shoutcast/icecast等Internet Radio,本质上就是HTTP流媒体的mp3/aac
于是我试了下,还真成功了。比如3fm alternative
最后边个参数是欺骗蹩脚DMR播放器MIME为mp3才能播放。
于是在罗技z906上成功实现听Internet Radio。想起来Android上支持DLNA的播放器还真不多。QQ视频支持。还不错。
如果手机有app支持直接push网络电台到DMR就爽了。看来得自己DIY一个哈哈。以后应该自己逐步实现audio book/podcast用上DLNA。
btw 发现这个upnp/dlna可以刷进路由器的 http://xupnpd.org/t/ 威武
Posted
archive
玩了一下Intel UPnP Device Spy很好玩
让设备播放媒体很简单:
python -m SimpleHTTPServer然后随便指定了一个avi。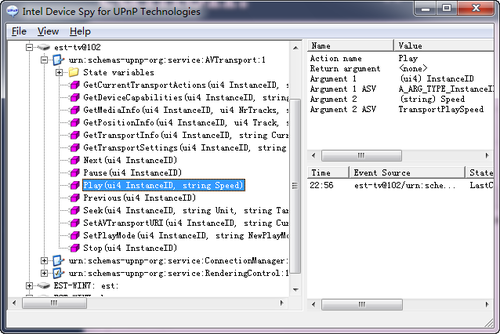
就OK了。
家里的网络有问题,找不到设备,找到设备也无法播放。Win7/Android 2.3/4.0之间的DLNA互通还是有问题。折腾ing。。。用的DMR设备是 com.waxrain.airplayer 。
btw DLNA国内翻译的貌似是 多屏互动 。
Posted
archive
终于搞清楚了几个概念。
DLNA是一套基于UPnP的4层协议,基于HTTP+SOAP的,是Sony在2004年提出的。
有如下几个角色:
DLNA没有去实现屏幕镜像。主要用于内容传输和播放。
Miracast是Android 4.2搞的,基于Wifi Direct技术
简单的说,就是同一个wifi AP下完成协议握手,然后两个设备之间wifi信号直连。这样效率高实时传输无延迟。Miracast也包含了DLNA的设备发现功能,和视频播放能力,但同时:
所谓屏幕镜像就是手机上打游戏在电视上同步围观这种。类似Windows的3389 RDP远程桌面和VNC。
Apple的AirPlay可以实现DLNA和Miracast的所有功能。
我觉得Apple的小圈子营销真的做的很好。Miracast的branding看来真的是一坨屎。光同一概念的子名词就有一大堆。Galaxy S III上把这个叫WLAN DIrect,Miracast的3层协议叫Wifi Direct/Wifi Display/TDLS。。。。。还有各种WFD, WIMO, WIDI, WHDI, WirelessHD。。。太多阿猫阿狗名字了。。orz真够混乱的。
参考:http://blog.sina.com.cn/s/blog_10bc1d030101aw97.html
Posted
archive
据说这样就行了
$ LD_PRELOAD="/usr/lib/libtcmalloc.so"
Posted
archive
《You aren’t imagining it: The web is a mess》这篇文章提出了一些比较犀利的观点:
Web已经乱死了。
我觉得,同理,现在blog圈子基本已经死了。不是外力杀死的,而死blog太讨好搜索引擎自杀的。Blog还没有 长微博 这种怪胎混得好。这是一种莫大的讽刺。
我突然想到一个指标用来判断网站好坏,阅读量。单位:人天。
一个标准人一天的阅读量是固定的。假设阅读效率为s。一个人每天花t时间上网,那么整天阅读量 R 就是:
R = s x t
如果一个网站每天更新的内容超过了 1人天,那么这个网站就是垃圾站。
一个网站的好坏,就在于是否用最小的篇幅,做到了最大可能的报道覆盖和最大量的信息传递。
覆盖面这个不太好判断,最大量的信息传递这个倒是有办法,就是语义比较相似网站的雷同报道。
搜索引擎一诞生,就是扮演者图书馆管理员的角色,在最短时间内找到最大量的最大匹配结果。这个做法是信息匮乏,和分布极端不均时代必要的生存手段;
但是现在不同了,现在是信息过载时代,单体的信息是非常容易获取,廉价和负价值的,集中的信息才有正价值。如果能够为普通人做到一个信息输入输出平衡的搜索引擎,才是最具含金量的搜索引擎。
过去的搜索引擎是空间上的军备竞赛,谁黑谁大谁粗,谁就牛逼;现在则到了一个转折点,谁能够更好的为用户安排更加有意义的时间,谁就是救世主。
目前这个领域唯一的玩家,只有Google。Google太掌握这个行星上每一个人每天的行为和习惯了。(在北美用过Google Now都会为这个玩意的AI震惊)。Google有能力,有足够原始数据积累,唯一缺乏的就是这样一个具有vision的目标和执行。
Posted
archive
The most depression thing today, is I found a solution to a problem from my OWN BLOG FOUR years ago!
Bottle.py's dev server auto-reloading sucks hell.
The child process will have os.environ['BOTTLE_CHILD'] set to True and start as a normal non-reloading app server. As soon as any of the loaded modules changes, the child process is terminated and re-spawned by the main process. Changes in template files will not trigger a reload. Please use debug mode to deactivate template caching.
The fact is it will neither reload, nor the child process will terminate when you Ctrl+C the main process.
Let's use Django's reloader for bottlepy development!
from bottle import run, Bottle
app = Bottle()
def dev_server():
run(app, host='0.0.0.0', port=8080, debug=True)
if '__main__' == __name__:
from django.utils import autoreload
autoreload.main(dev_server)
Everything went better than expected.
btw my Tumblr Markdown editor can not accept capital E and R, using PinYin IME is OK. strange!
Posted
archive
Running bottlepy with default server (wsgiref.simple_server) is always dog slow for me, after some digging I found that the fucking server is trying to resolve the IP address of 10.x.x.x, both the server and client, into hostnames so the fucking logger can 'properly' display them. FUCK THIS BULLSHIT.
Find BaseHTTPServer.py
Go to line 478;
def address_string(self):
return self.client_address[0]
It works best if you have virtualenv set you can just modify a copy in the lib only for development use.
Fuck who ever wrote BaseHTTPRequestHandler.address_string() FUCK YOU ASSHOLE. Who ever thought reverse DNS lookup is acceptable is pure piece of shit. It only spams your log with fake & gay spammer domains.
Bottle.py is great Web framework, it supports Async WSGI calls, which Flask can not do. . It works even without using gevent as server. I am thinking of adding some sessions support to it. db backend maybe?
Update: for python 2.6, just write this line for monkey patch before bottle.run() or wsgiref.simple_server
__import__('BaseHTTPServer').BaseHTTPRequestHandler.address_string = lambda x:x.client_address[0]
Posted
archive
It is a bit different than your standard FEC. Traditionally, FEC works on a block (of bits/bytes) by block basis. You need to the entire block to decode the message. So the transmitter needs a good guess on the channel capacity to choose the correct coding strength for the block. If the sender guesses wrong, the channel is either under utilized (sending too slow) or over utilized (lost packet). In practice it is hard to guess the channel state.
The novelty is their work is the use of network coding, a form of rateless coding. A rateless code does not operate on a block by block basis. Instead once enough bits are received, the message can be decoded. The rate automatically adapts to the channel's capacity because of the encoding/decoding of the code.
Rateless codes are also known by different names, e.g. fountain (LT) codes, raptor codes, tornado codes, hybrid-ARQ, strider codes, spinal codes, and in a sense network coding (though this may have more applications).
最近一篇paper在网上吵得很火,这段话基本总结了这个技术的思想。
纸:http://www.mit.edu/~medard/papers2011/Modeling%20Network%20Coded%20TCP.pdf
Posted
archive
在django.utils.functional 里发现的。
class cached_property(object):
"""
Decorator that creates converts a method with a single
self argument into a property cached on the instance.
"""
def __init__(self, func):
self.func = func
def __get__(self, instance, type):
res = instance.__dict__[self.func.__name__] = self.func(instance)
return res
这玩意好用啊,比如
>>> class A(object):
... @cached_property
... def val(self):
... print 'calc'
... return 1
...
>>>
>>> a=A()
>>> a.val
calc
1
>>> a.val
1
以前自己山寨个 def val(): self._val = 什么的太烂了。
Posted
archive
安装pv:
sudo apt-get install pv
下行:
$ ssh est@my_host 'cat /dev/zero' | pv > /dev/null
144kB 0:00:05 [ 121kB/s] [ <=> ]
上行:
$ yes | pv | ssh est@my_host "cat > /dev/null"
2.06MB 0:00:05 [1.96MB/s] [ <=> ]
测试本机IO能力:
$ pv /dev/zero > /dev/null
75.3GB 0:00:09 [8.56GB/s] [ <=> ]
其他技巧:
http://blog.urfix.com/9-tricks-pv-pipe-viewer/
恩。真好玩。我发现办公室的商用ADSL对称上下行就是屌啊。2MB上传速度我擦不用来挂PT可惜了。
Posted
archive
最近在android上玩RMaps Ext和Mobile Atlas Creator (MOBAC)
一直觉得tg的天地图其实道路信息和POI做的比其他厂商都好,所以网上找到了这个天地图版MOBAC
但是我发现一个很好玩的信息,跟我当时对天地图的感觉一样:天地图最大的问题不是163这种喷子媒体说的各种问题,而是:地图是扭曲的。
网上找到这篇文章《天地图-地图投影技术剖析与思考》
虽然图片jb全无,但是却得到了一个很有用的结论:
目前国内做数字城市方面的GIS项目、产品和公众应用,常涉及的投影方式主要有:面向局部区域的二维平面高斯投影(横轴墨卡托,横轴圆柱投影)、面向大范围(如全省、全国)的兰伯特投影(圆锥投影)、面向大范围的经纬度等间隔直投,而互联网上的大部分全国公众地图网站(百度、google、搜狗)则是另外一种-----“Web墨卡托”。
在市一级的小范围区域的GIS系统,比如规划局、国土局、建设局的系统,大都使用高斯投影,以便与地方地形图测绘、工程报建一直采用的坐标系相一致。高斯投影的特点也很明显,分带,适合小范围局部,不适合应用于大省、全国等大范围应用,若是强制按某带投影,则远离中央经线的区域的角度、距离、面积全部变形严重。
在大范围,目前好像很多项目都采用“经纬度直投”,------天地图也采用了。
Web墨卡托的问题是什么呢?
也许您还有疑问,“Web墨卡托”虽然形状没变,但是高纬度地区的面积比真实同样放大了很多倍,面积也是变化很严重啊!同一张全中国范围图上,三亚和哈尔滨,选取同样真实面积的区域,在投出来的图上面积相差好多倍,但是他们各自区域中的图形都没变型。
哇靠。怪不得天地图那个坐标比例看起来别扭死了。我擦。
Posted
archive
今天才知道的。windows下,干净hosts,可以nslookup 和 ping 的 ip 不一样。
主要是 Primary DNS suffix of this computer 这个功能。
解决方法也很简单,nslookup my.domain.tld. dns.server.ip
注意 tld 后边一个点。这样强制从根域来解析。
用这个方法可以来欺骗一些人,前提是获得主机域权限。
Posted
archive

一种说不出来的味道。
Posted
archive


When Alex Honnold and I discussed the Nikon D4 project several months prior, we locked in on Joshua Tree National Park. Given the area's dry weather in late November, J-Tree seemed to be the obvious climbing location. During our first phone call, we simultaneously suggested Equinox as the climb. At 5.12c, this is a test piece in Southern California climbing. On a rope, Alex is a top climber. Without a rope (free soloing), he is in a class unto himself. If Equinox felt good with a rope, there was a high likelihood he would be up to free solo the climb. Again, much like Dane, if Alex did decide to free solo the route, we might only have one opportunity to capture the ascent. Obviously, the stakes are very high, when a fall could mean death. To our amazement, after Alex's first lap he announced "it felt good, actually pretty easy". He then proceeded to do it two more times in the last 20 minutes before the sun set. On the second day of shooting with Alex, the tables had turned. He climbed to the crux (the hardest section of the climb), fiddled with getting good finger jams, was not feeling it and backed down. After a 20 or 30 minute rest, he was back on the wall, did one lap and called it. I really value and respect Alex's ability to listen to his mind and body and not allow any external forces to influence whether he climbed again or not.
video: https://vimeo.com/34666308
拍摄摄影君的摄影君才是神一般的存在啊。
Posted
archive
KDE那帮人觉得Dropbox不错于是搞了个山寨品 ownCloud.org 。我很是喜欢。
其中双向同步的关键核心组件是 csync,看了下,是OpenSUSE一帮人搞的类unison工具。
unison/csync 区别在于:
csync is a bidirectional file synchronizer like unison. csync is written in C and not in ocaml. So it can be used by PAM (pam_csync) or you can write a GUI for it (this is a future plan). csync is a client only file synchronizer and doesn’t need a daemon running on the other system. Unison needs to be installed and running on both systems.
希望csync能用上rsync的差分复制算法。这样就完美了。
关于ownCloud,赞美+吐槽几点:
希望能加几点:
有点心痒痒想跳进这个坑啦。非常有趣的项目。总的来说,ownCloud前途无量。他们也有商业版本 ownCloud.com。这个模式很好,可以说潜能是是把云计算真正做到了消费者零售这个级别。
Posted
archive
>>> import pprint, datetime, json, urllib2
>>> p=lambda:json.loads(urllib2.urlopen('http://radioplayer.omroep.nl/helper/now-on-air.json?ac=%s&channel_id=3' % datetime.datetime.now().strftime('%Y%m%d%H%M')).read())
>>> pprint.pprint(p()['current_song'])
or parsing this HTML
http://radioplayer.omroep.nl/helper/playlist.html?ac=201210101540&channel_id=3
ac is the timestamp. channel_id=3 is 3FM Serious Radio.
Posted
archive
Here's a handy python script do the job of uwsgi --ping <address>
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import unicode_literals, print_function
import socket
import struct
#---------------------------------------------------------------
#---------------------------------------------------------------
def ping_uwsgi(sock_file):
'''
Ping UWSGI process trought socket. Return [True,...] if OK,
return [False,error] if UWSGO not pinging, or
[None,error] if common error (ex. socket file not found)
'''
rv = [None,'']
fmt_h = str('<BHB')
sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
try:
sock.connect(sock_file)
except socket.error,e:
rv = [None,e]
sock = None
if (sock):
ping = struct.pack(fmt_h,100,0,0)
sock.send(ping)
pong = sock.recv(struct.calcsize(fmt_h))
sock.close()
p = struct.unpack(fmt_h,pong)
if (p == (100,0,1)):
rv = [True, 'OK']
else:
rv = [False, 'ERR']
return rv
#---------------------------------------------------------------
#---------------------------------------------------------------
via http://pypi.python.org/pypi/nust
Posted
archive
难得夜深人静反思一下。我个人每天12个小时在网上闲逛,自个觉得我现在有几个值得警惕的危险趋势:
输入越来越多,输出越来越少。创作能力退化。
个人觉得消费信息文化这个风气是由教主Steve Jobs带来的,以iPad为代表的纯内容消费平台给大家带来的各种使用的便利和享受的同时,也剥夺了一项至关重要的权利——创作和生产。
和PC相比,你既可以在上边消磨时光,但同时也可以用来当作生产力工具。我个人觉得PC平台是一种输入输出的平衡
而iPad这类平台不一样,这货带来的风气,就是一种consumer culture。在iPad上外接键盘打字都十分痛苦和不友好。你在上边能做的就是消费弱智游戏,消费视频,消费小清新照片。Android似乎友好一点,甚至android上直接编写android程序。办公什么的也有可行性,但是这也最多是先驱者的尝试和号称而已。
这个问题的各种衍生也深深影响了互联网。我觉得可以叫做consumerism。君不见各大博客、BBS、微博上,除了喷子就是小白。很少有人积极去invent有意义和价值东西了。
过多信息时效化。(我承认我现在患“语体教”病了,我很难找到一个词语来形容这个东西)具体的描述就是,人们更加关心失效性很快的东西,更加耸人听闻的东西,和心理落差更大的东西,而偏向忽略那些永恒的东西。比如关心某软件、ROM、OS的新特性,而不去关心整个业界的完备推进程度。就举一个简单例子。Steve Jobs很喜欢声讨Flash怎么烂怎么搓,但是他从来不告诉你作为一个移动设备的 矢量+音视频多媒体引擎 应该做成什么样子。我们过多的去关心如何打倒Flash,如何打倒IE6,新技术如何做到Flash 10年前也能做的东西,比如apple.com上的wwdc现在都还在用Quicktime®(而不是html5 video)来播放流媒体;在HTML5喧嚣的今天,人们甚至通过WOFF这种奇技淫巧来绘制矢量图标。这是一种悲哀,和对SVG莫大的讽刺。
碎片化。这个就不说了。但同时我觉得我还有另外一个很显然的毛病——老了。各种怀旧各种经典,很少去接触新事物了。手上天天操作和玩的东西,和几年前的并没有实质上的差别。
流行的东西就是王道。即使小众的领域里,相对流行的也能秒杀其他的。人们宁愿附和各种lame的meme,也比自己写一段nobody cares的东西更加有归属感。其实我觉得这个是生态圈的问题。每个个人的能力是有限的,你在一个注定forever alone的小圈子里,是很少能得到反馈的。你甚至渴望信噪比很低的反馈。
信噪比。我觉得现在一个最最最浮躁,但是又欲罢不能的问题就是各种重复信息。各种repost简直是强奸你的接受器官。但是你miss了一系列之后又觉得自己真2b。花那么多时间在网上连这个最泛滥的东西都不知道。各种第三方的aggregate工具,由于依靠全自动化算法,所以coverage由成问题。现在对话题的关注精力投入远远大于收获。
各种挖坑不填。其实最消耗精力的就是没有结局的故事。了结的事情总是让人舒坦。但是现在千头万绪的信息,有始有终的太少啦。新事物,新自造轮子的产生速度大于问题的产生速度。这种让人无所适从。坑多就不说了,我还讨厌选择。所以进一步导致更多的放弃。我越来越发现 问题 - 解决方案 这种线性思路越来越不适应需要了。我现在需要的是一种全新的面向变化的结构。
人物为中心的世界。我十分吃力的去人物化。
我渴望一个SNS,隔绝与hivemind的各种hype,又能自洽。这是一种neo utopia么?我觉得这是我这种introvert的人的病。明明知道任何群体都有4个阶段:适应 - 指数增 - 平衡 - 衰亡。这是注定的命运。
上诉问题都是我个人自己点滴感受。当然,这和我个人所处的环境有关,或许其他人的感受不是这样的。或许只是我自己所处的环境太糟糕了。个性化的互联网就是这样,你很难看到客观一致的东西,你看到的都是你自身的影子。你自己是个挫人,那么你关注的人群也基本都很挫,你得到的东西也是很挫的。
Posted
archive
上次看到 Google后Hadoop时代的新“三驾马车”——Caffeine、Pregel、Dremel
感觉碉堡了。
Pregel是一个graph db。这是逆NoSQL运动行之的潮流——NoSQL倡导没有join,而graph db则是——所有数据都可以默认join起来。
Dremel 是一个query interface。
Caffeine的背后是Google True Time API,这是基于Google Spanner的一个碉堡技术。。
什么是Google Spanner?Spanner是一个行星级别的db系统——通过GPS、原子钟实现全球数据中心timestamp同步的MVCC。
和BigTable相比,BigTable的cell是mutable,Spanner是Datomic,类似函数式变成里的常量;Spanner还提供了BigTable不具备的——分布式transaction支持。比如lock-free read transaction
隐隐的感觉Google的天顶星科技碉堡了。paper都非常值得一读。。。虽然不明,但觉历。
Posted
archive
以前发过一个良民证算法
现在发现了一个碉堡的新办法:
get_id = lambda s: s + '1X864209753'[int(s, 13) % 11]
来自newsmth的python版:
发信人: Andor (珍惜), 信区: Python
标 题: Re: Python的良民证算法,有没有更简单的写法?
发信站: 水木社区 (Fri Sep 14 15:13:05 2012), 站内
get_id = lambda s: s + '1X864209753'[int(s, 13) % 11]
【 在 zxn0 (est) 的大作中提到: 】
: >>> get_id = lambda s: s+'10X98765432'[reduce(int.__add__, map(lambda
: a,b:int(a)*(ord(b)-64), s[0:17], 'GIJEHDBAFCGIJEHDB' )) % 11]
: >>> get_id('34052419800101001')
: '34052419800101001X'
: 大家看哪里还能精简字符不?
发信人: Fermat (Fermat), 信区: Python
标 题: Re: Python的良民证算法,有没有更简单的写法?
发信站: 水木社区 (Mon Sep 17 01:41:42 2012), 站内
既然 int(s, 13) 这么漂亮的都出来了,又何必把那么好记的 "10X98765432" 弄成一个 magic number 呢
get_id = lambda s: s + '10X98765432'[(int(s, 13)*13) % 11]
或者在有32位整数限制的地方使用类似的
get_id = lambda s: s + '10X98765432'[((int(s, 13)%11)*13)%11]
对于有算法洁癖的,下面的可能会好些
from itertools import chain
get_id = lambda s: s + '10X98765432'[reduce(lambda acc, x:
(acc*13 + int(x)) % 11, chain(s, "0"), 0)]
因为可以把输入字符串当成个无限流,且程序只占用少量固定的空间,也不需要语言对很大的整型有支持。虽然对这个程序没啥意义。
关于良民证,python普通版描述在这里,前六位的来自官方 县及县以上行政区划代码
Posted
archive

{kind=link}