LLM, RAG 和 Groq
Posted | stderr
最近跟朋友聊起LLM,RAG 究竟有没有用,能不能拿来做成产品或者服务。由于我对AI的了解也很肤浅,所以没太敢下结论。
但是今天突然想起一个趣事,相传 账单·大门 院士有一句名言「640KB ought to be enough for anybody」
这句话是不是他老人家说的不重要了,重要的是 IBM PC 的这个 640KB内存 的梗是绕不过去了。

后来发现 640KB 不够了怎么办?屎山上接着hack呗。于是发明了 EMM386 ,在CONFIG.SYS 里吟唱一句
DEVICE=C:\DOS\HIMEM.SYS
可以保平安。
如果人人都能用 Gemini 1.5 Pro 那个 1M context tokens, 那么 RAG 技术也没啥用了吧。猜想能用 RAG 卖钱的,估计跟定制 HIMEM.SYS 和 EMM386.EXE 的市场一样。。。。。在 PC 普及的初期是一个神级,但是随着日本政府主导 VLSI产业+三星DRAM的崛起和价格战,一切都成了历史。
又想起另外一件事:Groq
也是啥都不懂,翻了些资料,发现比较有意思。CUDA vs Groq 可以看成DRAM vs SRAM。context window不足的问题:
疯石头 2024-02-23 02-21: Context window到100K后,即使batch=1,GPT-3级别的大模型,KV-cache占显存的容量已经比weight要大了。实际部署时batch size至少得64才能用上tensor core。4-bit quant可以降到1/4,GQA group=8时可以再降1/8,不过还是比weight要大。sliding window不可取,遗忘问题会完全丢掉long context的优势。
更详细的讲解:
https://kipp.ly/transformer-inference-arithmetic/#kv-cache
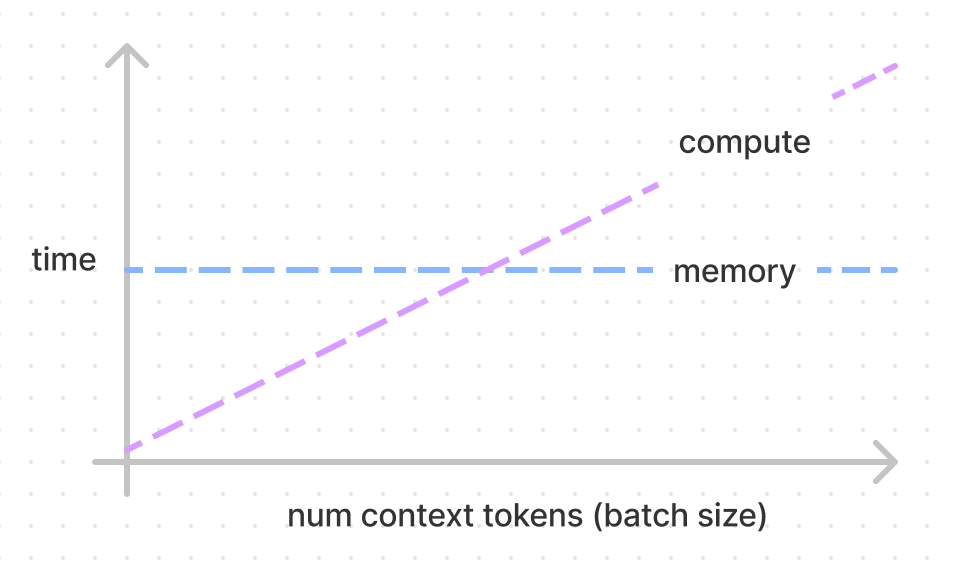
在zhihu上翻到一些资料说,LLM推理主要成本不是矩阵计算,而是 memory access。可惜帖子找不到了。
Comments