China's AI Dominance Does Not Depend On Math
Posted | stdout
There was a not-so-interesting article on reddit that says China's Race For AI Dominance Depends On Math
The arguments looks flawed in several ways.
First of all, yes Chinese students do performs well in math, but only in one narrow specific branch of math: alrithmetics. Once they graduate into college, most Chinese suck at Advanced Math (高数), as described in this story
很久很久以前,在拉格朗日(Lagrange)照耀下,有几座城:分别是常微分方城(程)和偏微分方城(程)这两座兄弟城,还有数理方城(程)、随机过城(程)。从这几座城里流出了几条溪,比较著名的有:柯溪(Cauchy)、数学分溪、泛函分溪、回归分溪、时序分溪等。其中某几条溪和支流汇聚在一起,形成了解析几河、微分几河、黎曼几河三条大河。
河岸边长了一种树,叫 高数,上面挂了很多人。
Secondly, even the most advanced AI requires, astonishingly, rudimentary Math, the most Math-y part of AI are Statistics, Probability and Linear Algebra, e.g. matrics. You don't need a Math PhD to grind some ML or DL stuff.
Next for AI in real life, a really big part is the domain insight plus the engineering skills, how something works in theory is one thing and how to scale a model to millions of users and create profits for business is totally different, and way more challenging for many AI scientists.
Lastly, in my opinion, the secret of China's AI dominance relies on data.
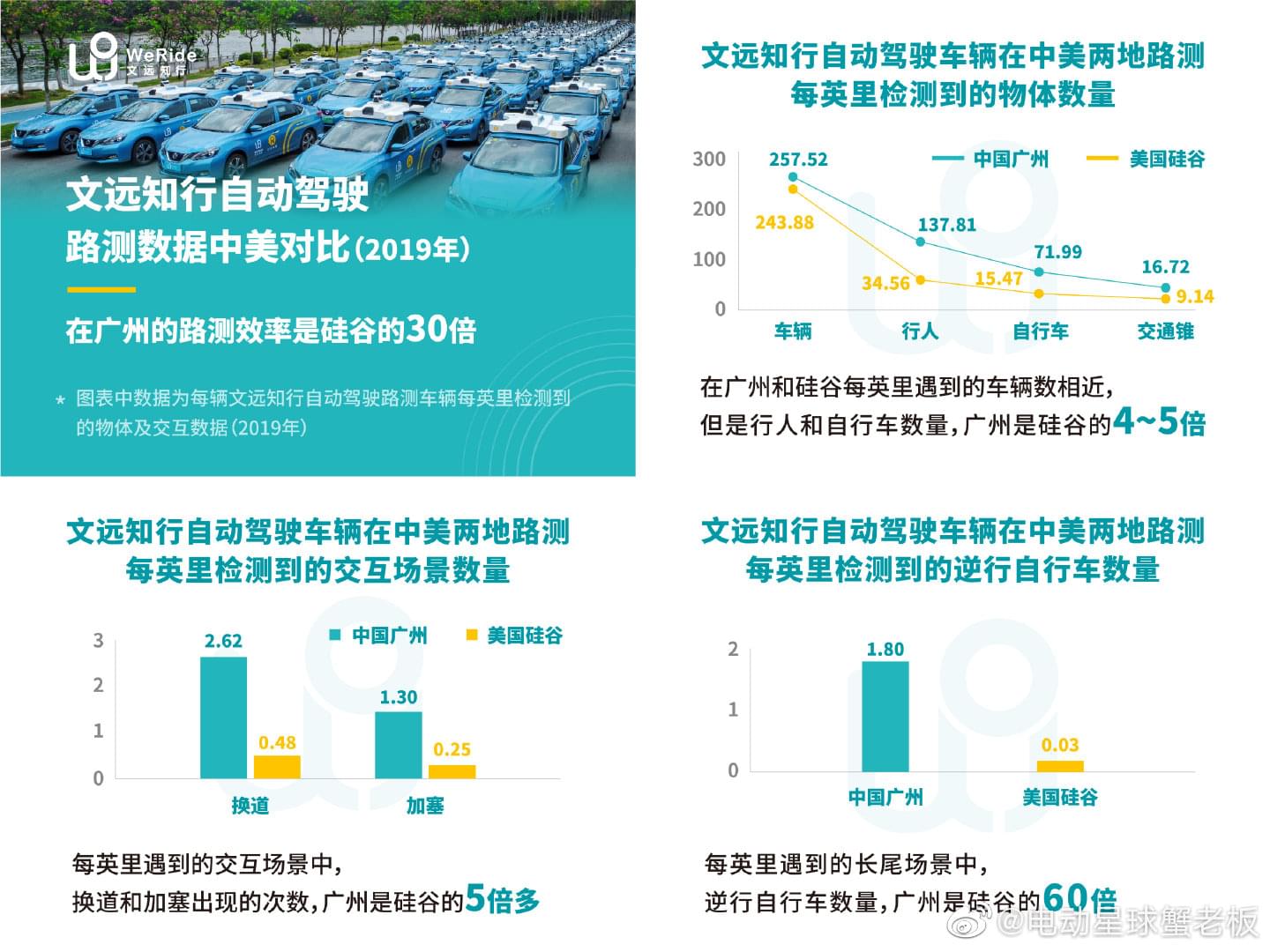
One of the Chinese auto-driving startups, WeRide, published a 2019 research, they compared the hundres of driving data between Sillicon Valley and Guangzhou, in which they found:
- For every mile, there was a similar number of vehicles in both places, but 4x to 5x times the pedestrians and bikes.
- Line cutting and lane switching is 5 times more often in Guangzhou
- There was 60x occurances of bikes riding in the wrong direction each mile.
The massive, unregulated, aggregated, labled-by-hand and privacy invasive data is the coal to this AI revolution, mathematics is just the STEAM engine. (pun intended)
Comments